
Overview
High Availability is a term used to describe a system which leverages multiple redundant servers and standby systems that protect the (overall) system, from the failure of any part.
Traditionally, companies would go to great lengths and make exorbitant investments in building and managing separate data-centers to achieve this style of protection.
Since the advent of cloud providers such as Amazon (with its AWS offering) and Microsoft (with its Azure offering), creating resilient systems has become relatively easy. However, despite the ease of creation, many companies are still forgoing high availability (HA) architectures because of perceived costs in terms of operation or, in terms of complexity.
For this installment of ‘Show Create:’ I will create an API using Python-Django. I will then deploy the system with servers, in multiple zones, and with a resilient Database. With minor changes to the set up scripts I will create this system in both AWS and Azure.
AWS as a cloud provider has the largest footprint of services, capacity and capability. The AWS cloud market share is dominant. It has managed to maintain this dominance. AWS’ cloud market share as it stands, is steady at 33% in Q1 2019. This is the same as one year earlier in Q1 2018, according to the latest numbers from Synergy Research.
AWS accounts have access to multiple regions around the world. Each region is divided into 3 physically separated zones called ‘availability zones’. Should any zone become unavailable, as does happen from time to time, the other zones can provide equivalent service during the outage.
Some companies, in their deployment of AWS, make the mistake of treating AWS instances as physical machines, and deploying systems in a single AZ. A HA system must use at least two AZs for servers. Depending on the importance of the system it may be necessary to deploy to multiple AZs in multiple regions. To be ‘highly available’, in its most authentic definition and meaning, merely redundancy is not enough. The system must be able to respond quickly to increasing load from either normal traffic increases or the possibility of DDOS attacks. Any fixed system must be designed with excessive capability to cope with these scenarios. In a cloud environment we can dynamically utilise more resources as needed to keep up with demand.
What we’ll build
For this example the servers will be spread across 3 AZs in a single region.
Each region will contain a system to automatically scale in the event of a load spike or other event such as the loss of an AZ.
Components:
in AWS we have a VPC with one subnet per AZ.
Each django server will run on a single instance.
In each subnet, we will set up:
- a Target-Group
- an AutoScaling-Group or ASG
- a launch template for creating new django-servers
In the VPC as a whole we will add an ELB for distributing requests to running django servers. We will need a database – AWS provides resilient and scalable databases in the RDS service. We could, however, use master slave replication in a database set up similar to the Django API system, but RDS is definitely the better tool.
To deploy this system I have written some bash scripts which call the AWS command line interface, to create these assets.

The django system itself is stored in a git repository which is checked out during the launch on the server or ‘instance’.
To achieve that, the launch template for an instance contains a bash script which runs on the launch or restart of any instance in the fleet. Other options might be to attach a volume from a snapshot of the system or create a custom AMI for launching
The API is a simple, single model, which returns a list of fruit as a JSON object.
Using TastyPie for Django, the API lets us use POST to create a new fruit entry, PUT to update fruit entries and GET to obtain either the full list or details of an individual entry. This is the kind of component a company might use to publish product data to online retailers or maintain data-flow of stock levels or other realtime information.
The servers will be using the ‘not for production’ internal server. This server may fail in any instance and is therefore a good way to test the resiliency of our system. In this system it is the architecture which is providing HA not the individual components.
Time to run the creation script.
The create-asg-template-and-target-group.sh contains 11 lines. It performs these tasks:
- create load balancer
- create target group
- create launch template
- create a listener on the load balancer
- create one autoscaling-group per AZ
- attach those three ASGs to the target group
These tasks take approximately 30 seconds to complete.
In the configuration for the ASGs I ask for a single instance to be created.
What we end up with is three instances; each running in a different AZ. A load balancer which can accept requests on behalf of the fleet and route the requests to each of the AZs. Three ASGs which monitor the health (am I working) and the load (can I keep up) of the instances ready to respond to load or network events.
Right now we can consider this system to be highly available. If there was a loss of power in one AZ the API would still be available from the other two AZs. If an asteroid strike took out two AZs, the third would be able to maintain the system.
With the sudden loss of two AZs, load would likely increase on the remaining instance and the ASG would deploy new instances to take on the traffic.
How to test it
Soak and Load.
It would be nice if we could test the scaling aspects of our API. In fact, we can use the same script to create a load runner. Instead of setting up the Django server on new instances I can instead add a cron task with a call to apache-bench to make a fixed number of requests every minute while the instance is running. For this system, I can set the parameters in the ASG to create 5,10 or 100 nodes, each one making the same requests every minute.
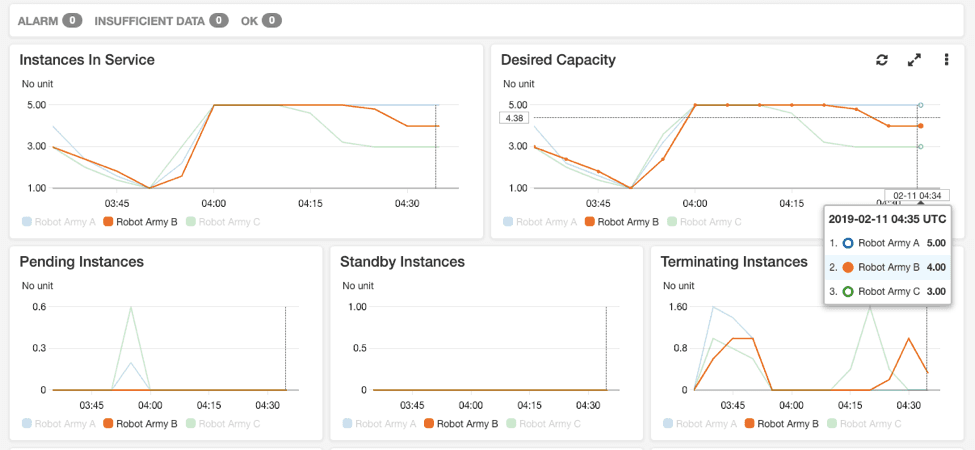
We can watch the load and the responses from the AWS console. There is monitoring enabled by default, we can also set up group metrics on the ASGs to get a better summary of scaling behavior.
$> aws autoscaling enable-metrics-collection –auto-scaling-group-name ‘Robot Army A’ –granularity “1Minute”
With the second system running – I can make these changes to the Load-Runner system and watch the API respond to the load in the monitoring tab of the ASG.
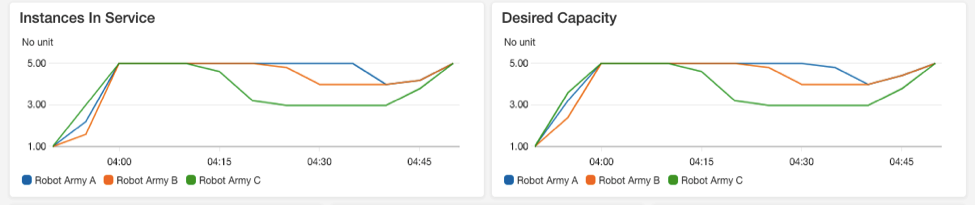
Once the API ASGs have stabilised, we can then simulate network events by deleting instances in the EC2 panel, or blocking some ports in a subnet. If loads in any ASG increase beyond its set equilibrium point, the ASG will scale out to take the load. Once I scale down the load runner, the ASGs in the API system will detect the decrease and automatically scale-in according to the rules set in the ASG parameters.
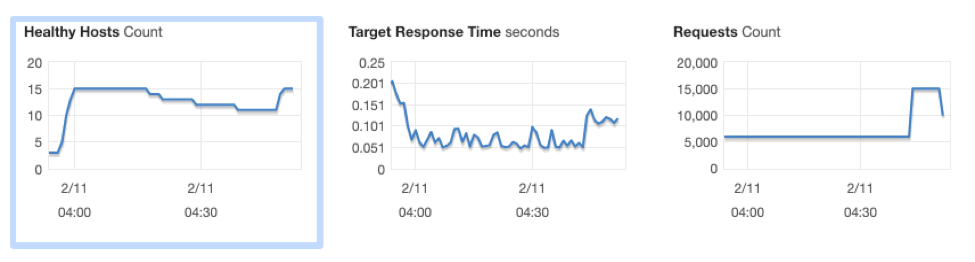
Conclusion
This project was an enjoyable way to elucidate the ease of creation of a highly available system using AWS autoscaling and load balancing. Our system took advantage of multiple availability zones meaning that any failure of network access or AWS hardware would not bring down our service. Any failure of a server would be detected by the auto-scaling-group and a new instance would automatically be launched to maintain our preferred state. Any high loads experienced by the groups would trigger additional instances to be added to the fleet to maintain both service availability and speed. Finally we reused by code and concepts to create a load-runner service to soak-and-load the API.
If you would like to learn more about building or testing high availablity systems using AWS autoscaling, feel free to contact us or email us at [email protected]



